

In an ideal world, sustainability data wouldn’t be as complicated as it is. In reality, data is often fragmented, inconsistent, or simply missing in action. How are you meant to manage your risks, plan your strategies, and meet regulatory requirements, if there are blanks in the picture?
As the market demands more comprehensive and reliable data, the focus turns to the gaps. How do we fill them without compromising on integrity?
That is where our machine learning (ML) framework comes in. We use advanced ML workflows to infer missing quantitative metrics with market-leading precision. By combining disclosed data with sophisticated ML-powered estimates, we provide a 360-degree view of organisational impact that is both decision-ready and auditable.
What is ML estimation?
ML Estimation is the process of using verified data patterns to predict missing metrics; allowing us to move away from working with incomplete information and toward a scientific approach where every estimated value is grounded in real-world operational and environmental correlations. At GIST Impact, we integrate a broad spectrum of inputs ranging from financial and business characteristics to environmental and sector-specific metrics to address data gaps. These are further supported by country and region-specific insights.
How do we ensure standardisation?
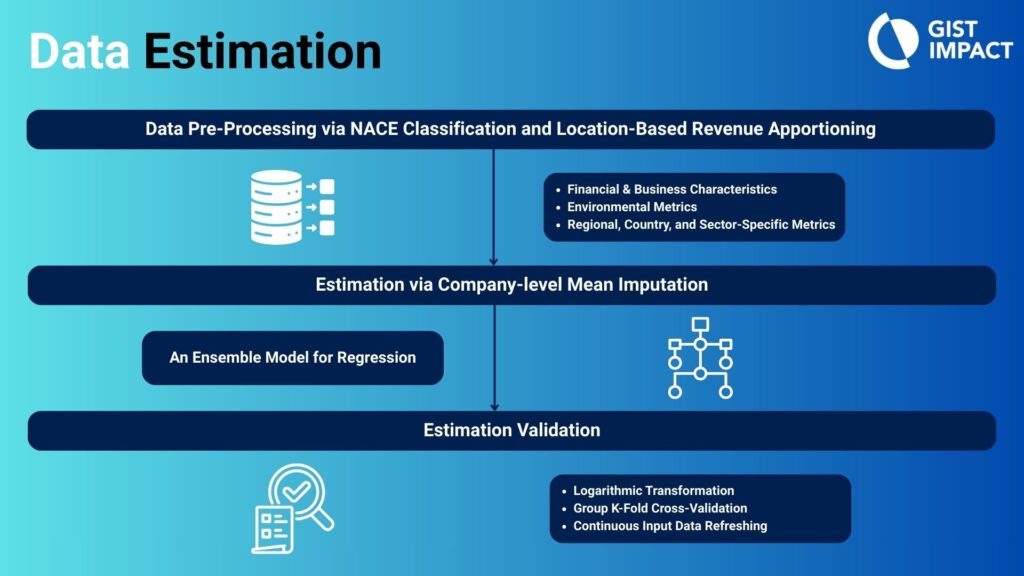
Before a single estimation is made, we prepare the data to establish analytical consistency.
- NACE Classification: We begin by mapping all business operations to the NACE system, allowing for both broad sectoral overviews and granular, activity-specific analysis.
- Geographic Granularity: We then transform location-specific revenue (using ISO codes) into geographic percentage allocations. This allows our ML models to understand exactly where a company is operating and how it is influencing its environment.
What is our strategy?
To train a model you can rely on, the training set itself must be robust. We use company-level mean imputation to address missing values while preserving temporal trends. Company-level mean imputation involves using internal company data to fill data gaps to maintain organisation-specific accuracy and consistency across its global footprint.
Our primary estimation tool is an ensemble model for regression. Think of this as a team of “digital experts”, or decision trees, working in a sequence.
A decision tree is an algorithm that maps out potential outcomes in a flowchart-like structure. In our ensemble model, each new tree is designed specifically to correct the errors of the one before it. This iterative process allows the model to “learn” from its own performance, gradually sharpening its accuracy until the final prediction is as close to real-world data as possible.
How do we ensure scalability and validate our estimations?
To ensure our estimations hold up under scrutiny and can be applied at scale, we apply a multi-layered validation process:
- Logarithmic Transformation: To handle extreme variances in corporate data, we compress wide numerical ranges using a logarithmic scale. This allows the model to process outliers effectively without distorting the results.
- Cross-Validation: We use the Group K- Fold cross validation technique to test the model multiple times on “unseen” data to ensure its predictions remain accurate across different scenarios and sectors, and prevent any data leakages.
- Continuous Data Refreshing: We are constantly crawling and capturing higher volumes of input data to ensure that our model is always trained on the most current information available, keeping our insights perfectly in sync with the real-world landscape.
Transparency in every value
At GIST Impact, just as with our disclosed data, transparency is paramount. Our methodology is fully documented and accessible, and we distinguish between disclosed and estimated values so that you can report with confidence, knowing exactly where your data came from and how it was arrived at.
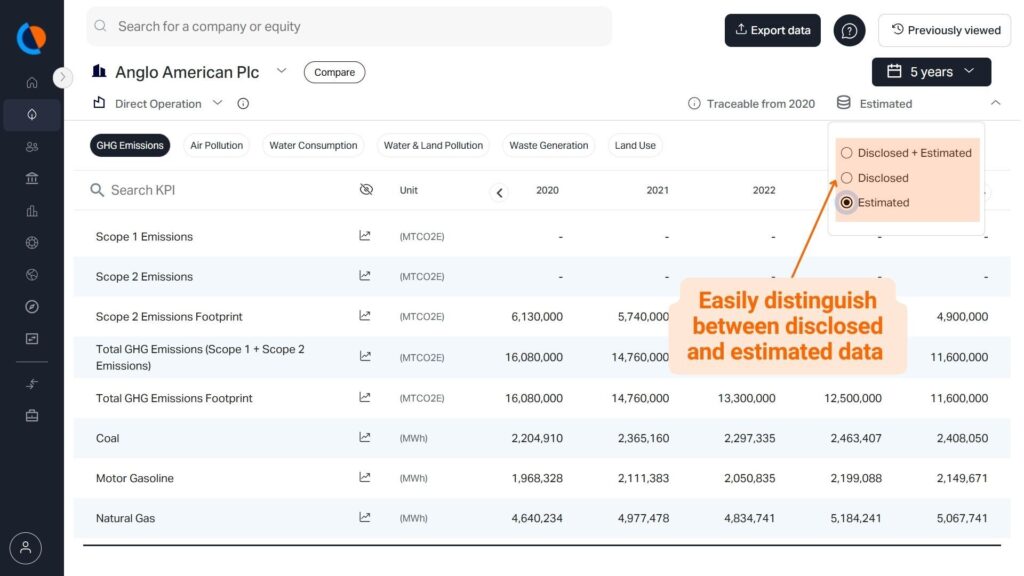
Distinguishing between disclosed and/or estimated data is easily done on our portal.
The purpose of this explainer is to give a broad overview of our approach to missing data. In practice, a number of additional methodological steps, validations, and refinements sit behind the simplified process described here. If you’d like to explore the technical details further, our team would be happy to walk you through it.
Contact our team for a demo to see our ML estimation capability in action.

